
Tech Babble #10: Vega, shaders and GCN.
- Sasha W.

- Feb 29, 2020
- 7 min read
Updated: Aug 15, 2020
UPDATE 15-08-2020: Please read my Knowledge Update on RDNA's Primitive Shaders!
I wanted to type a Tech Babble on this subject. I was going to include some bits about GCN in general, and also about Ray Tracing on these processors, but this one will be limited to talking about Vega in general, and my thoughts and opinions on this often considered, 'ill-fated' Graphics Processor.
Die size and transistor count.
I'll start by addressing this subject. Over the years since Vega launched back in 2017, a lot of people have criticised it for being 'too big' or having 'too many transistors' for the level of (3D Gaming) performance it offers. If you compare it to Nvidia's Pascal architecture, it doesn't look all that great on paper. Performance in games is similar to the 314mm2 GP104, with 7.2 billion transistors. In comparison, Vega 10 is 486mm2 and contains 12.5 billion transistors.
If you compare these numbers, some people probably ask why Vega needs so many more transistors to provide the same level of performance in 3D graphics in games. To address this first subject, I really must take a look further back at GCN itself, and what this architecture was actually designed to do.
Some previous pieces on GCN that I have typed can be found here:
Summary: GCN Compute Unit, a Paralell computing monster.
But, I will summarise here. GCN was designed to be a highly parallel computing architecture able to get around certain dependencies in code. Since 1st Generation GCN in late 2011 to 2012, with the 'Tahiti' GPU; the fundamental computing 'core' of GCN has remained the same - only with AMD's recent 'RDNA' architecture and 'Navi' series of GPUs has the CU actually changed dramatically in structure and the way it operates.
Firstly let's take a look at the structure of a Compute Unit, found in the GCN.
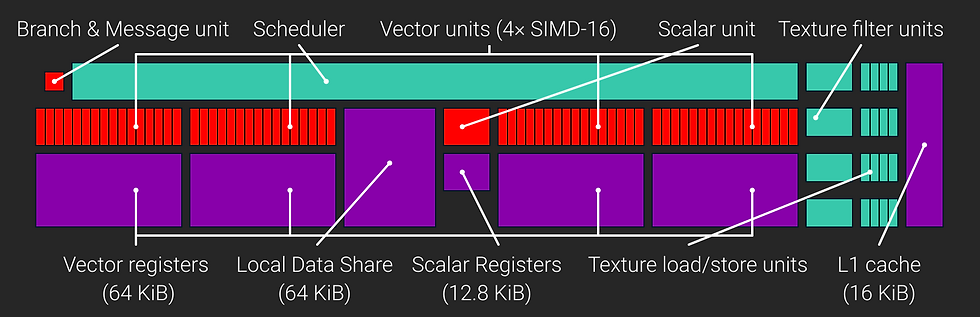
The basic functional units of the CU consist of the Vector units, which actually perform the calculations on shader code, the Scalar units which operate on single numbers, Branch and Message unit which handles branch-based code (If/Else) and the Texture load/store units with the filtering units nearby. This post is primarily about the Vector SIMD units.
To understand how this graphics 'core' works, we have to break it down into chunks of mathmatical processors:
SIMD-16 - "16 stream processors"
SIMD-16 - "16 stream processors"
SIMD-16 - "16 stream processors"
SIMD-16 - "16 stream processors"
With GCN, AMD's driver dispatches work for the Compute unit in groups of threads/numbers called 'Wavefronts'. Each Wavefront is composed of 64 threads/numbers - this is called a Wave64. You might be forgiven for thinking that since a single Compute Unit consists of "64 stream processors" altogether (as we see above), that the Wave64 can be done in a single operation, or clock cycle on all four of Vector units. This is not the case.
This picture from Anandtech's review of GCN is fantastic at describing how the CU works with these numbers:

At the top you can see there are four Wavefronts, each with 64 numbers/threads each. Each Wavefront contains four groups of instructions to be operated on 16 numbers simulatenously, this is called Single Instruction Multiple Data (SIMD). In order to extract maximum parallelism from this design (also presumably to address VLIW's innate disadvantage with dependent instructions), the GCN Compute Unit works on 4 wavefronts at once, with each SIMD-16 vector unit calculating on of its four instructions.
GCN, Vega: an under-utilised beast in games
For simplicity's sake, I'll summarise the important bit here. The Compute Unit can only issue a new Wavefront for calculation every four clock cycles. Advantages of this include excellent parallell number calculation capability, but a downside that actually affects GCN's ability to maintain high utilisation in games due to the tendency for many games to issue short dispatches of work for shader code, (i.e, only a single Wavefront is needed for that operation at that time). The result is;
Compute Unit can work on up to 4 Wave64s, completing all 4 in 4 clocks.
On the other hand, if only one Wave64 is needed, it still takes 4 clocks to complete just one.
The result is a parallel computing core that if fully saturated can crunch an enormous amount of numbers. But also, shader-code (and to an extent drivers) need to be able to pipeline instructions into the CU very well, in order to achieve full utilisation.
Ever wondered why Vega has 4096 SP but performs similar, at not-particularly-much-lower clock speeds than GP104's 2560 SP, in games? That is not because Vega's SP's are 'weaker' it is because the game isn't utilising all 4 Wavefront slots. Perhaps that shader only achieves utilisation on 2 or maybe 3 of those slots; ultimately, some SIMD-16 units are idling while the Compute Unit spits out those waves, before being able to be issued a new set of Waves.
By the way, adding more Compute Units does in fact improve performance on GCN - even though it is underutilised - that is because there would be more CU ready to recieve a new Wavefront, as the others are busy working over 4 clock cycles.
This is an 'issue' with GCN, and by extension, Vega, in gaming workloads. This is also something that 'RDNA' and 'Navi' has addressed. That architecture potentially trades some parallelism for the ability to dispatch new waves every clock cycle with a new, smaller Wavefront of 32, or every 2 clocks (still 2X as fast as GCN) when running GCN-legacy Wave64 code.
If you ever noticed how GCN-based GPUs such as Vega can vary in gaming performance hugely. That is because different types of shaders align themselves better with GCN, while others might only make very small, latency-sensitive dispatches. GCN is all about throughput, at the expense of latency.
Sash thought: Consider that overclocking the memory on GCN, something always considered to be 'bandwidth-limited' in games, might be improving performance by reducing latency to memory, rather than increasing bandwidth?
An enhancement in 4th Generation GCN 'Polaris' was to allow the CU to prefetch instructions, potentially helping pipeline them to occupy the Compute Unit more efficiently.
Geometry. Is it even a weakness for Vega?
This is an interesting one for me, because for a while I was also supporting the idea that Vega was in fact limited by geometry performance in modern games. This might not actually be the case. Vega's geometry pipeline is very capable - incorporating an improved Primitive Discard Engine from the previous 'Polaris' design; an engine that can discard zero-area, or denegnerate (invisible) triangles before the GPU can draw them - otherwise wasting clock cycles drawing something that the user cannot see. It also has a huge L2 cache to keep more geoemtery data on chip and can re-use vertex data from earlier in the pipeline.
I can't tell you for a fact if Vega is limited by geometry in certain games, the chances are it might be, but I am sure without reasonable doubt that Tessellation and geometry was never a real issue for Vega because of this next subject.
The Truth about Vega's Primitive Shaders.
One of the major 'features' of Vega as advertised was the ability for the GPU to combine vertex and geometry shaders together, innately, and use this process to spit out vastly higher amounts of triangles per clock. For a long time, people were waiting for 'Vega's Secret sauce' as it were, but it never came. Eventually, it was learned that AMD had dropped innate Primitive Shader support from the driver entirely; relegating it to simply a developer-coded feature. The general consensus was that the functionality was broken on the Vega silicon.
Fast foward to today and I don't believe this was the case. I have learned from multiple sources and talking to people with knowledge on this subject, that the Primitive Shader was actually fully functional in Vega; it just didn't improve performance overall. If you read the first section about the way Vega's graphics SIMD cores work, you'll probably start to see where I'm going with this.
The truth likely is, (can't confirm, but very sure) that combining those shader stages and the subsequent increase in triangle discard/output, was simply not reducing frame-times on Vega because the Graphics Engine was still limited by shader occupancy.
In fact, I have heard it from very reliable sources that Vega was achieving only around 60-70% occupancy in very well optimised games such as Wolfenstein II: The New Colossus. That really does speak volumes about what is going inside Vega.
Vega isn't broken. Games just don't use it fully.
The Draw-Stream Binning Rasteriser. Is it working?
Another major feature advertised for Vega, was for the GPU to essentially break the frame up into smaller 'bins' and render them in serial, rather than render the entire frame as one object. This is essentially a tile-based rendering method similar to the one NVIDIA has implemented since Maxwell. It was often asssumed that the DSBR was not functioning, but it almost certainly is. DSBR's primary advantage is in keeping more working data for each bin on the chip, without having to require the full memory amount for the entire scene. This reduces bandwidth reliance and lowers power consumption.
The primary application for Vega's DSBR would actually be on the mobile APU parts, where the integrated Vega GPU is heavily bandwidth constrained. On the desktop, the DSBR helps Vega (along with the larger L2 cache and better colour compression) acheieve a healthy performance increase over its spiritual predecessor, Fiji, despite actually possessing less raw memory bandwidth.
RDNA: Addressing the GCN occupancy issue
If we look at what AMD changed with the new 'Navi' generation of GPUs based on RDNA, it would seem to directly confirm what I've typed here. RDNA's SIMD unit is changed drastically to allow for much lower dispatch latency and thus higher utilisation in bursty gaming workloads - including higher 'single-threaded' performance. GPUs are very good at hiding latency, but gaming graphics workloads are also latency sensitive. RDNA's changes prove that AMD has addressed that.
Conclusion
I think it's safe to say that Vega isn't a broken GPU. It's not half-finished, it's just a double-edged sword of a paralell computing monster that it is. To this day, Vega is one of the most powerful GPU computing architectures available, if it's lots and lots of numbers you want to crunch.
Unfortunately, while gaming graphics often involves lots of number crunching, the balance of latency and throughput was tipped out of Vega's favour, leaving the beast unfed.
Thanks for reading. <3
Comments